湾区同学技术沙龙
(Bay Area) Snowflake / Databricks / OceanBase
3 September 2022
1:00PM ~ 6:00PM, 9/3/2022, Saturday
Registration
- Registration link: www.meetup.com/bay-area-multi-cloud-infra-group/events/287777156/
- Event link: (Bay Area) Snowflake / Databricks / OceanBase
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:00PM ~ 6:00PM, 9/3/2022, Saturday
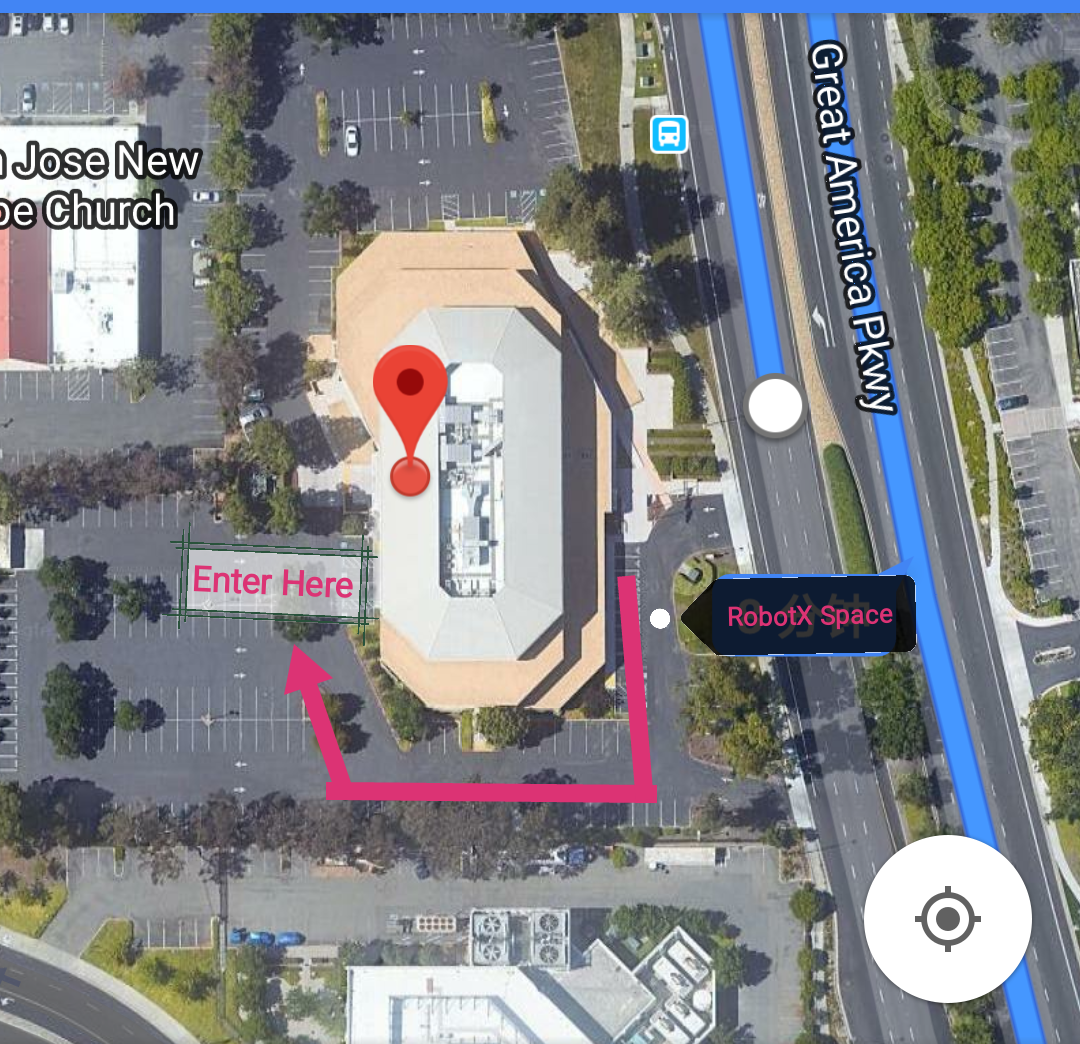
- Location: Plug and Play HQ, 440 N Wolfe Rd, Sunnyvale, CA
- Language: English
Agenda
- 13:30 - 14:00 Check In
- 14:00 - 14:50 A Decade of OceanBase: Performance, Architecture, and Evolution 🎙️Charlie Yang, OceanBase
- 14:50 - 15:40 The Snowflake Data Cloud: a New Type of Cloud Dedicated to Data Analytics. 🎙️Jiaqi Yan, Snowflake
- 15:40 - 16:00 Coffee Break & Speed Networking
- 16:00 - 16:50 Databricks Photon: A Fast Query Engine for Lakehouse Systems 🎙️Gene Pang, Databricks
- 16:50 - 17:20 Lightning talk: 61 Million QPS Challenge in Alipay: How Did We Do It 🎙️Ted Bai, OceanBase/Alipay
Details
👋 Hello, Engineer! Welcome to the first event of the Bay Area Data Infrastructure Meetup. Our goal is to share technical insights and best practices in this area and get engineers connected. Whether you are a developer, ops pro, system engineer, or any other IT professional excited about infrastructure technologies, the Bay Area Data Infrastructure Meetup will have something for you.
- 📹 Webniar: https://us06web.zoom.us/j/87965510656?pwd=RUpLTXlxcURmODhzT2JqdUhLL1VyQT09
🍮🍺 Snacks and drinks will be provided.
👬We are going to hold a series of activities in the Bay Area, and looking forward to your warm participation. If you are interested in sharing your experiences – either as speakers or as users – kindly contact us: ailing.tal@alibaba-inc.com
Speakers
Jiaqi Yan is a Principal Software Engineer at Snowflake Computing. He primarily leads development efforts for the Compiler and Optimizer of the Snowflake Database, along with Workload Optimization, as well as Automation and Diagnostic Infrastructure in the Query Engine. Prior to joining Snowflake, Jiaqi worked as a Senior Member of Technical Staff for Oracle Database's Query Engine.
Gene Pang is a software engineer at Databricks, on the Photon Engine team. He is working on various Photon components such as window functions, sorting and aggregations. Before joining Databricks, Gene worked on distributed systems at Alluxio, and received his Ph.D. from UC Berkeley. His interests are in the areas of databases and distributed systems.
Charlie Yang is CTO at OceanBase. He joined Alibaba&Ant Group in 2010 as the first developer of OceanBase, led the architecture evolution and TPC benchmark test of OceanBase, he is leading the development and product team of OceanBase. Before joining Alibaba&Ant Group, he was Baidu's senior distributed system engineer. His research interest includes database, distributed system, and the cloud.
Ted Bai is the solution architect at OceanBase. He is working on designing and implementing scalable and resilient database solution for users in varies industries. Ted is also a former member of OceanBase SRE DBA team in Alipay. As a senior expert, he has been leading database migration and performance tuning projects in many mission-critical systems. In addition, Ted was also the owner of Alipay Digital Finance business on OceanBase.
主办
- Bay Area Multi-Cloud Infra Group
- Ant Group HQ, Sunnyvale
- OceanBase OceanBase.com
- 湾区同学技术沙龙(TechM)
- 南京大学硅谷校友会
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
- 长城会 RobotX Space
(Bay Area) 云端数据中台:数据编排与平台运维
15 September 2019
1:30PM ~ 4:00PM, 9/15/2019, Sunday
Registration
- Registration link: tech-meetup-9-15-2019.eventbrite.com/
- Event link: (Bay Area) 云端数据中台:数据编排与平台运维
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:30PM ~ 4:00PM, 9/15/2019, Sunday
- Location: 1st Floor Pitch Room, 4500 Great America Parkway, Santa Clara 95054 (ZGC Innovation Center)
- Language: Chinese
Agenda
- 1:30pm - 2:00pm: Reception and social time
- 2:00pm - 3:30pm: Talk+ Q&A
- 3:30pm - 4:30pm: Offline networking
Talk1: 如何把Alerts减少两个数量级: EA数据平台在云端运维的探索与演进
Abstract: Today, one can easily launch or terminate services with hundreds or thousands of compute instances in just a few seconds on cloud services such as AWS. However, operating, monitoring and maintaining those resources could also easily become a nightmare if the corresponding tooling systems were not designed in a cloud-native way.
Detail: In this talk, we share our lessons in building and rebuilding a cloud-native monitoring system to solve this problem at Electronic Arts (EA). In the first generation of the monitoring system, configurations were manually created for many individual software components and spread over all the resources. As services were started and terminated rapidly over time, it was extremely difficult to keep all the configurations up to date. Consequently, on average we received over 1,000 alerts from thousands of machines on a daily basis, which stressed the operations team. We redesigned the system in late 2018 in a project called Monitoring As Code (MAC) emphasizing on version control and automation. MAC manages all the configurations using a GIT project in the same way as software code. Moreover, it establishes standards so that the configurations are automatically generated and deployed to keep everything in sync. As a result, it reduced the daily average number of alerts by two orders of magnitude. A big data problem is reduced to a small data problem for human productivity and operational efficiency.
Speaker Bio: The speaker, Du Li, is currently an Architect of Big Data Infrastructure at Electronic Arts. He earned his BS from Wuhan University, MS from Peking University, and PhD from UCLA. He worked in academia and industrial labs for many years. Prior to joining EA in mid-2018, he worked at Yahoo and Apple as a senior software engineer.
Talk2: 基于Raft,gRPC,RocksDB和高并发算法打造存储10亿个文件的高效元数据服务
Abstract: 起源于UC Berkeley AMPLab的Alluxio是一个被百度、腾讯、华为、沃尔玛、Twosigma等行业巨头在云端广泛应用的开源数据编排系统。它的设计初衷之一包括能够高效存储并服务超大规模的文件系统中所有文件和目录的元数据。
Detail: 本演讲将分享Alluxio元数据服务(master节点)的架构,实现和优化,以解决可扩展性挑战。我们将特别介绍如何设计和应用合多个前沿工程技术和实践,包括基于堆外KV store RocksDB实现分层级的元数据存储,细粒度文件系统inode树锁方案,基于Raft分布式共识协议的master多节点高可用方案,以及社区对gRPC系统的探索和实践。结合上述技术,Alluxio 2.0的元数据服务能够存储至少10亿个文件,并在显着降低内存需求的同时扩展到3000个worker节点并为30000个客户端提供服务。
Speaker Bio: 范斌是Alluxio公司的创始成员与, Alluxio开源项目的PMC成员. 加入Alluxio团队前, 范斌在Google从事下一代大规模分布式存储系统的研究与开发. 范斌博士毕业于卡内基梅隆大学计算机系, 博士期间在分布式系统算法和系统实现等方向发表多篇包括SIGCOMM, SOSP, NSDI等顶级论文, 设计和实现了CuckooFilter,MemC3以及libCuckoo.
主办
- 湾区同学技术沙龙(TechM)
- ZGC Innovation Center
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
- 长城会 RobotX Space
(Bay Area) Google Doc 是如何炼成的 - 深入浅出协同编辑/Deep Dive Collaborative Editing
18 August 2019
1:30PM ~ 4:00PM, 8/18/2019, Sunday
Registration
- Registration link: tech-meetup-8-18-2019.eventbrite.com/
- Event link: (Bay Area) Google Doc 是如何炼成的 - 深入浅出协同编辑/Deep Dive Collaborative Editing
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:30PM ~ 4:00PM, 8/18/2019, Sunday
- Location: 1st Floor Pitch Room, 4500 Great America Parkway, Santa Clara 95054 (ZGC Innovation Center)
- Language: Chinese
Agenda
- 1:30pm - 2:00pm: Reception and social time
- 2:00pm - 3:30pm: Talk+ Q&A
- 3:30pm - 4:30pm: Offline networking
Talk Abstract:
随着互联网技术的发展,越来越多的企业协同软件都内嵌了实施协同编辑功能,从最早的鼻祖GoogleDocs, 到Quip, 再到最新流行的Notion 等等; 今天我们想就实时协同编辑技术进行深入浅出的探讨。
Speakers' bio
郑文涛:现任字节跳动旗下产品Lark(飞书)企业邮箱业务负责人,之前在Google GSuite 带领技术团队打造了两款从0到1的产品:Hangouts Chat 和 Jamboard.
主办
- 湾区同学技术沙龙(TechM)
- ZGC Innovation Center
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
- 长城会 RobotX Space
(Bay Area) An introduction of Analytics Zoo and how to use it at Uber
21 July 2019
1:30PM ~ 5:00PM, 7/21/2019, Sunday
Registration
- Registration link: tech-meetup-07-21-2019.eventbrite.com/
- Event link: (Bay Area) An introduction of Analytics Zoo and how to use it at Uber
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:30PM ~ 5:00PM, 7/21/2019, Sunday
- Location: 1st Floor Pitch Room, 4500 Great America Parkway, Santa Clara 95054 (ZGC Innovation Center)
- Language: Chinese
Agenda
- 1:30pm - 2:00pm: Reception and social time
- 2:00pm - 3:20pm: Deep Learning on Sensor Data with Analytics Zoo at Uber + Q&A
- 3:20pm - 3:30pm: Break
- 3:30pm - 4:50pm: Analytics Zoo Introduction + Q&A
- 4:50pm - 5:10pm: offline networking
Talk 1: Deep Learning on Sensor Data with Analytics Zoo at Uber(Speaker: Lucinda Zhao)
Uber processes TBs of sensor data daily to build better products. For example crash detection with which operators can reach out to drivers who are detected going through accidents to provide prompt guidance and support. Sensor data is one important input to such applications.
Sensor data is ideal for Deep Learning. However, overhead for DL dev and productionisation is large -- most frameworks focus only on model training (forward/backward propagation) whereas data ingestion, model integration, pipeline management etc are left behind. Those steps may end up eating up big chunk of dev cycle. AnalyticsZoo fills in the missing pieces.
In this talk we will provide overall experience feedback for DL on large-scale business data with AnalyticsZoo from users’ point of view: how the workflow looks like, how AZ helps boost dev/productionisation efficiency in DL and what are the potential concerns. Overall it’s definitely a framework worth onboarding when live in the Hadoop-Spark BigData-DL ecosystem.
Lucinda(Luyu) Zhao: ML engineer at Sensor Intelligence team of Uber. Joined Uber in 2015 she has worked on various projects utilizing sensor data to provide inferences and insights. Before Uber she worked at Qualcomm designing baseband signal processing algorithm and architecture. She has background and production level first hand experience in big data, machine learning, wireless communication and signal processing.

Talk 2: An Introduction to Analytics Zoo: Distributed TensorFlow, Kerasand BigDLon Apache Spark (Yuhao Yang)
Analytics-Zoo是基于Apache Spark以及BigDL的开源分布式深度学习框架(https://github.com/intel-analytics/analytics-zoo)。它为Spark提供了深入学习功能的原生支持,同时为现成的使用单节点志强Xeon CPU的开源深度学习框架(如Caffe和Torch)带来了数量级的性能速度提升,并为它们提供了基于Spark架构的对深度学习任务的高效的水平扩展的能力;此外,它还允许数据科学家使用熟悉的工具(包括Python和Notebook等)来对大数据进行分布式深度学习分析。在这次演讲中,我们将演示大数据用户和数据科学家如何使用Analytics-Zoo以分布式方式对海量数据进行深度学习分析(如图像识别、对象检测、NLP等)。这可以让他们使用已有的大数据集群(例如Apache Hadoop和Spark)来作为数据存储、数据处理和挖掘、特征工程、传统的(非深度)机器学习和深度学习工作负载的统一数据分析平台。
Yuhao Yang: senior software engineer on the big data team at Intel, where he focuses on deep learning algorithms and applications—particularly distributed deep learning and machine learning solutions for fraud detection, recommendation, speech recognition, and visual perception. He’s also an active contributor to Apache Spark MLlib.

主办
- 湾区同学技术沙龙(TechM)
- ZGC Innovation Center
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
(Bay Area) Tensorflow.JS: Bringing Machine Learning To The Web And Beyond
19 May 2019
1:30PM ~ 4:00PM, 5/19/2019, Sunday
注意:场地容量有限,为确保有兴趣的同学能听到我们的讲座,每张门票收取$10,到场的同学会全额退款。
Registration
- Registration link: tech-meetup-5-19-2019.eventbrite.com/
- Event link: (Bay Area) Tensorflow.JS: Bringing Machine Learning To The Web And Beyond
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:30PM ~ 4:00PM, 5/19/2019, Sunday
- Location: 1st Floor Pitch Room, 4500 Great America Parkway, Santa Clara 95054 (ZGC Innovation Center)
- Language: Chinese
Agenda
- 1:30pm - 2:00pm: Reception and social time
- 2:00pm - 3:30pm: Talk+ Q&A
- 3:30pm - 4:30pm: Offline networking
Talk Abstract:
Machine Learning is a powerful tool that offers unique opportunities for JavaScript developers. This is why we created TensorFlow.js, a library for training and deploying ML models in the browser and in Node.js. In this talk, you will learn about the TensorFlow.js ecosystem: how to bring an existing ML model into your JS app and re-train the model using your data. We’ll also go over our efforts beyond the browser to bring ML to platforms such as WeChat, Raspberry Pi, and Electron, and we’ll do a live demo of some of our favorite and unique applications!
机器学习是一个强大的工具,为JavaScript开发人员提供了独特的机会。 TensorFlow.js正是为此而生,TensorFlow.js是一个用于在浏览器和Node.js中训练以及部署机器学习模型的库。 在本次演讲中,您将了解TensorFlow.js生态系统:如何将现有机器学习模型引入您的JS应用程序并使用您的数据重新训练模型。 我们还将努力跨出浏览器,将ML带入微信,Raspberry Pi和Electron等平台,我们将对我们最喜欢和最独特的应用程序进行现场演示!
Speakers' bio
Ping Yu是Google Brain的高级工程师,他致力于tensorflow.js,旨在弥合机器学习和javascript开发人员之间的差距。他也是谷歌attribution产品的Tech Lead.
在谷歌工作之前,Ping在许多行业(网络、安全、医疗)工作。他拥有丰富的经验,可以帮助公司使用敏捷流程开发web和移动应用程序。
Ping 在业余时间喜欢打网球和乒乓球。
主办
- 湾区同学技术沙龙(TechM)
- ZGC Innovation Center
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
See the index for more articles.